| . |
|
||||||
|
|
| . |
|
||||||
| Les
acides nuclĂŠiques
ADN et ARN |
| Les
acides
nuclĂŠiques (ADN et ARN) sont des macromolĂŠcules biologiques formĂŠes
de phosphore (P), de carbone, d'hydrogène,
d'oxygène et d'azote. Ces atomes sont rÊuunis
au sein des acides nuclĂŠiques dans des structures appelĂŠes nuclĂŠotides;
chaque nuclĂŠotide se compose d'un sucre pentose
(dĂŠsoxyribose pour l'ADN et ribose pour l'ARN), d'une base
azotĂŠe (adĂŠnine, cytosine, guanine et
thymine ou uracile) et d'un groupe phosphate.
ConservĂŠs au fil de l'ĂŠvolution de tous les organismes vivants, les acides nuclĂŠiques stockent et transmettent des informations hĂŠrĂŠditaires. Ils portent le schĂŠma gĂŠnĂŠtique d'une cellule et contiennent des instructions pour le fonctionnement de la cellule. Les deux principaux types d'acides nuclĂŠiques sont l'acide dĂŠsoxyribonuclĂŠique (ADN) et l'acide ribonuclĂŠique (ARN). Le flux d'informations
gĂŠnĂŠtiques est gĂŠnĂŠralement : ADN ADN et ARNL'ADN et l'ARN sont les macromolĂŠcules les plus importantes pour assurer la continuitĂŠ du vivant.L'ADN.
L'ADN est le matÊriel gÊnÊtique prÊsent dans tous les organismes vivants, allant des bactÊries unicellulaires aux mammifères multicellulaires. On le trouve dans le noyau des eucaryotes et dans les organites, les chloroplastes et les mitochondries. Chez les procaryotes (archÊes, bactÊries), l'ADN n'est pas enfermÊ dans une enveloppe membraneuse. L'ADN a une structure double hÊlicoïdale avec les deux brins s'Êtendant dans des directions opposÊes (antiparallèles), reliÊs par des liaisons hydrogène et complÊmentaires l'un de l'autre. Dans l'ADN, les purines (adÊnine et guanine) s'associent aux pyrimidines (cytosine et thymine) : les paires d'adÊnine avec la thymine (A-T) et les paires de cytosine avec la guanine (C-G). On donne le nom de gÊnome à l'ensemble du contenu gÊnÊtique d'une cellule, et l'Êtude des gÊnomes s'appelle la gÊnomique. Dans les cellules eucaryotes (contrairement à ce que l'on observe chez les procaryotes), l'ADN forme un complexe avec des protÊines (les histones), pour former la chromatine, qui est la substance des chromosomes eucaryotes. Un chromosome peut
contenir des dizaines de milliers de gènes. De nombreux gènes contiennent
les informations nĂŠcessaires Ă la fabrication de produits protĂŠiques;
d'autres gènes codent les produits de l'ARN. L'ADN contrôle toutes les
activitÊs cellulaires en activant ou dÊsactivant les gènes.
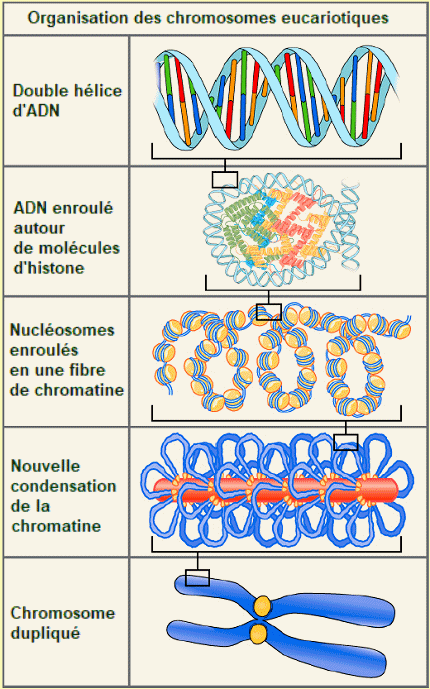
Compactage d'un chromosome eucaryote. - Chaque chromosome renferme une longue molĂŠcule d'ADN, enroulĂŠe Ă des histones. Les nuclĂŠosomes contiennent environ 200 paires de nuclĂŠotides. L'ARN.
Les molĂŠcules d'ADN
ne quittent jamais le noyau mais utilisent plutĂ´t un intermĂŠdiaire pour
communiquer avec le reste de la cellule. Cet intermĂŠdiaire est l'autre
type d'acide nuclĂŠique, l'ARN, en l'occurence l'ARN messager (ARNm), qui
est principalement impliquÊ dans la synthèse des protÊines. D'autres
variĂŠtĂŠs d'ARN : l'ARNt et le microARN, similaires Ă l'ARN, sont
impliquÊs eux aussi dans la synthèse des protÊines et la rÊgulation
de celles-ci.
Les nuclĂŠotides.
Les
bases azotĂŠes.
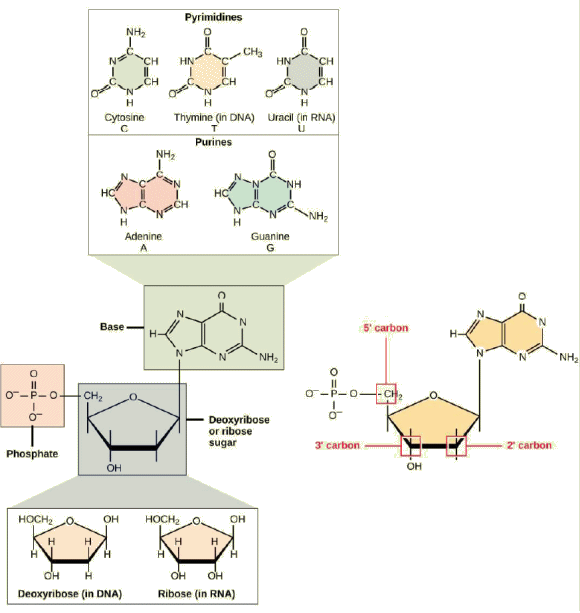
Chaque nuclÊotide de l'ADN contient, on l'a dit, l'une des quatre bases azotÊes possibles : l'adÊnine (A), la guanine (G), la cytosine (C) et la thymine (T). ⢠L'adÊnine et la guanine sont rangÊes parmi les purines. La structure primaire d'une purine est constituÊe de deux cycles carbone-azote.Chacun de ces cycles basiques carbone-azote a diffÊrents groupes fonctionnels qui lui sont attachÊs. Les
sucres et la liaison phosphodiester.
Les atomes de carbone de la molÊcule de sucre sont numÊrotÊs comme 1' (lire "un prime"), 2', 3 ', 4' et 5 '. Le rÊsidu phosphate est attachÊ au groupe hydroxyle de l'atome de carbone 5' d'un sucre et au groupe hydroxyle de l'atome de carbone 3' du sucre du nuclÊotide suivant, qui forme une liaison phosphodiester 5'-3 '. La liaison phosphodiester n'est pas formÊe par une simple rÊaction de dÊshydratation comme les autres liaisons reliant les monomères dans les macromolÊcules : sa formation implique l'Êlimination de deux groupes phosphate. Un polynuclÊotide peut avoir des milliers de telles liaisons phosphodiester. |
| . |
|
|
|||||||||||||||||||||||||||||||
|
